I had a file of about a thousand lines containing the full description of multiple products (audio plugins from Plugin Alliance in my case). The file starts like this:
249
19.99
Mixland
Vac Attack★★★★★
A warm harmonically-rich optical limiter for compression with tube saturation that’s great on vocals, drums, basses, and your stereo bus.
Hardware EmulationsHidden GemsPA MembersSale
89.99
29.99
Woodlands Studio
VOXILLION★★★★★
A stunning and sophisticated, and complete vocal chain in one streamlined workflow. Featuring a high-end blend of a tube-driven preamp, two types of compressors, Nasal Dynamic EQs, Harmonics and more
Hidden GemsLimited Time OnlyPA_EXTSale
279
39.99
ADPTR AUDIO
Metric AB★★★★★
The mastering engineer’s best friend: Compare your mix to your favorite reference tracks. See,hear and learn even more with new expanded features.
Hidden GemsMasteringSale
and ends like this:
FreeDownload
PA FREE
bx_shredspread★★★★★
Intelligent M/S width for doubled riff guitars. Auto-avoid common phase problems, and sound extra-wide and tight!
FREEGuitar & BassHidden GemsM/S InsideMade by BX
FreeDownload
PA FREE
bx_tuner★★★★☆
Accurate tuning for guitar & bass with useful features like volume dimming. Tune up right before you hit the record button.
FREEGuitar & BassMade by BXSale
FreeDownload
PA FREE
bx_yellowdrive★★★★★
Warm to crunch to shred with this classic “Yellow” pedal in plugin form.
Creative FXFREEGuitar & BassHardware EmulationsMade by BXSale
What I wanted to do was to split the long file of a thousand lines into smaller files, each containing the lines corresponding to one plugin only.
gawk -v RS= '{ print > ("plugin-" NR ".txt")}' plugins.txt
As explained in the solution, “setting RS to null tells (g)awk to use one or more blank lines as the record separator. Then one can simply use NR to set the name of the file corresponding to each new record”. As explained in the comment, this will fail with the basic version of awk as it cannot handle too many open files at the same time (only 252 files were created with awk). Switching to gawk works great and now I have 277 files which I can further process.
Then, a few weeks ago, I heard from cloud.mu, who were willing to sponsor a server for mirror purposes. That was just perfect timing. I had started discussions with an ISP but then cloud.mu was not just willing to provide the server & bandwidth resources but their speed to deploy and assist was even more commendable.
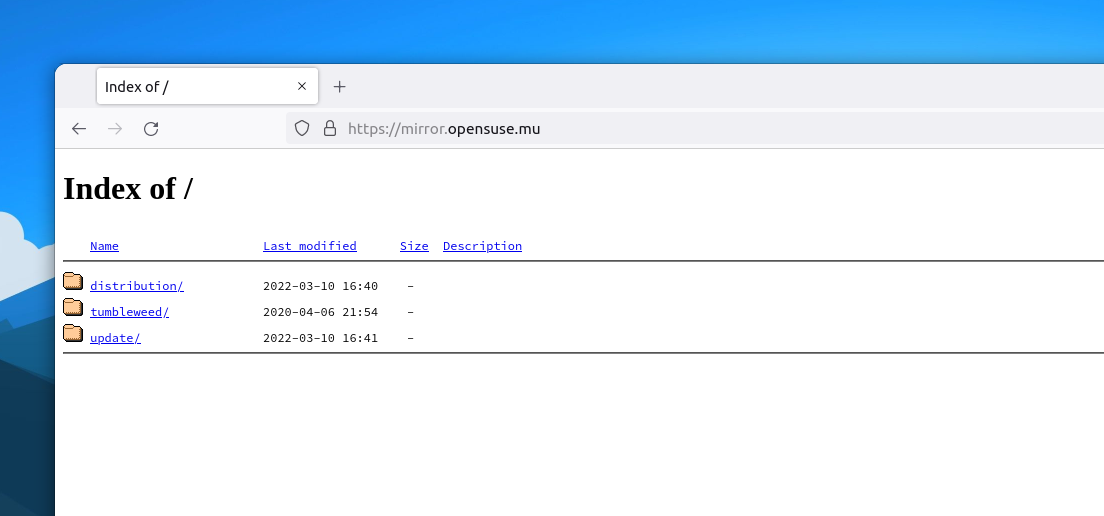
Once the server was ready, the next step was to contact openSUSE admins to update the DNS records for opensuse.mu. I sent my request to the openSUSE Board for the purchase the domain a long time ago. Until now I used to run a small blog for openSUSE tips & tutorials on opensuse.mu. The domain is owned by SUSE and mananged by the openSUSE admins, i.e the Heroes team.
After a few trials to sync from rsync.opensuse.org and other mirrors closer to Mauritius, I contacted the Heroes to get access to stage.opensuse.org, the restricted rsync server of openSUSE. After that, it was a matter of a few days to sync all that content.
Finally, the openSUSE mirror for Mauritius was ready.
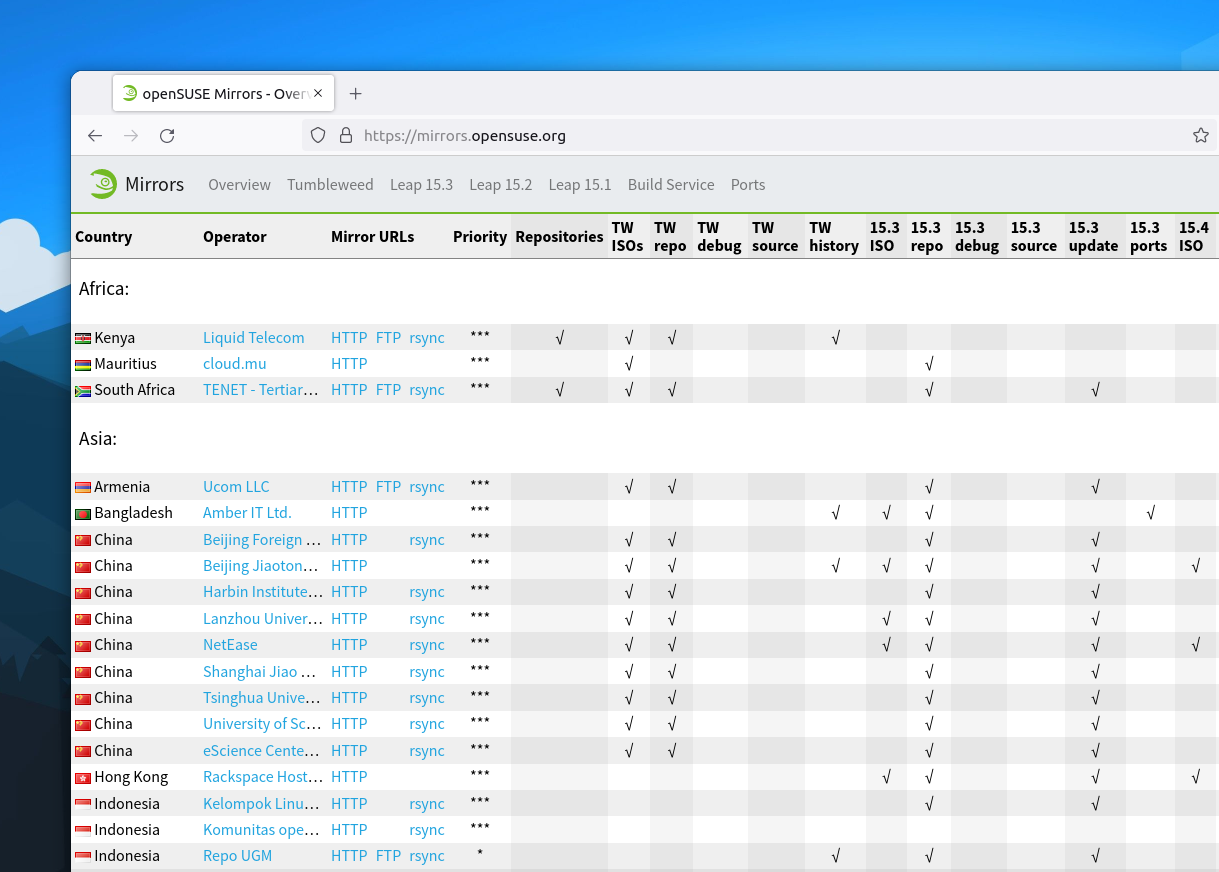
Compared to other regions, where there are several mirrors in the same country, the whole African continent had only two openSUSE mirrors until now. One managed by TENET (Tertiary Education and Research Network) in South Africa and the other one by Liquid Telecom in Kenya. Mauritius joins that list as the third mirror in the African region, thanks to cloud.mu.
How to switch to the openSUSE Mauritius mirror?
Switching to the Mauritian mirror is easy. First, remove the current repos that you have by either running zypper lr to identify them and zypper rr repo-name to remove the repos, or go to /etc/zypp/repos.d and remove the .repo files of the openSUSE repositories. If you have repos for other applications, e.g Google Chrome, VS Code etc, leave them.
Then, if you're using Leap, you can the Leap 15.3 OSS, Non-OSS and Update repositories.
sudo zypper ar https://mirror.opensuse.mu/distribution/leap/15.3/repo/oss openSUSE-Leap-OSS
sudo zypper ar https://mirror.opensuse.mu/distribution/leap/15.3/repo/non-oss openSUSE-Leap-Non-OSS
sudo zypper ar https://mirror.opensuse.mu/update/leap/15.3/oss openSUSE-Leap-Update-OSS
sudo zypper ar https://mirror.opensuse.mu/update/leap/15.3/non-oss openSUSE-Leap-Update-Non-OSS
If you're using Tumbleweed, then add the following repositories.
sudo zypper ar https://mirror.opensuse.mu/tumbleweed/repo/oss openSUSE-Tumbleweed-OSS
sudo zypper ar https://mirror.opensuse.mu/tumbleweed/repo/non-oss openSUSE-Tumbleweed-Non-OSS
sudo zypper ar https://mirror.opensuse.mu/update/tumbleweed openSUSE-Tumbleweed-Update-OSS
The mirror contains files for the x86_64 architecture only. If there is a need for other architectures, I'll do the necessary. Ping me on social media or send a mail to [email protected].
Why writing a blog article about the installation of Microsoft SQL Server 2019, related command-line tools, and UI-based management solution despite the official documentation by Microsoft?
There are two main reasons:
For own purpose and reference with some additional hints
The official documentation seems to be “out-of-sync”
However, as mentioned, some information feels out of picture or eventually outdated given existence of newer versions of the referenced applications.
Prepare your system
Before we shall start with the installation of SQL Server 2019, command-line tools and related management software let’s be sure that our local system is up-to-date and has the needed packages already installed.
Open a terminal to run the following commands. First one is going to update your local package cache. The second one installs the curl package which we are going to need for future commands.
Don’t ignore the trailing dash (-) in the command above. It is essential and therefore necessary. Alternatively this could have been done using wget like so.
curl https://packages.microsoft.com/config/ubuntu/20.04/mssql-server-2019.list | sudo tee /etc/apt/sources.list.d/mssql-server-2019.list
Then add the package repository for the command-line tools provided by Microsoft accordingly.
curl https://packages.microsoft.com/config/ubuntu/20.04/prod.list | sudo tee /etc/apt/sources.list.d/msprod.list
Alternatively the information of each package repository could be used directly. Here are the corresponding entries for the sources and some more.
# SQL Server 2019
deb [arch=amd64,armhf,arm64] https://packages.microsoft.com/ubuntu/20.04/mssql-server-2019 focal main
# SQL command-line tools as part of the "productivity collection"
deb [arch=amd64,armhf,arm64] https://packages.microsoft.com/ubuntu/20.04/prod focal main
# A few additional Microsoft repos for reference...
# Edge
deb [arch=amd64] http://packages.microsoft.com/repos/edge/ stable main
# Azure CLI
deb [arch=amd64] https://packages.microsoft.com/repos/azure-cli/ focal main
# Visual Studio Code
deb [arch=amd64,arm64,armhf] http://packages.microsoft.com/repos/code stable main
Maybe you prefer to store all Microsoft package sources in one single microsoft.list file rather than having multiple ones.
With the newly added repositories for apt it is time again to update the local package cache and to fill it with details about the new packages available.
sudo apt update
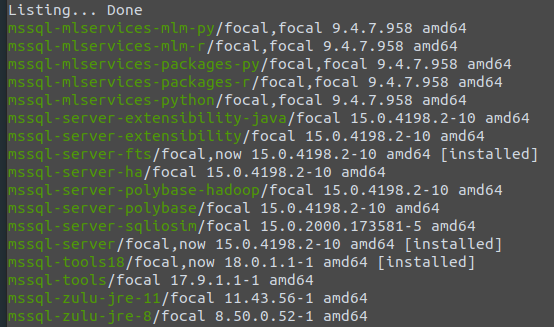
After successful update of the package cache you are able to search it for SQL Server related packages, like so.
apt search mssql
Or if you prefer less details, like this.
apt list mssql*
The output of the command above is going to give a list of available packages for SQL Server 2019. Your choice might be different but I’m going to install the actual database engine, with full-text search, the latest command-line tools, and additionally ODBC driver support for Unix/Linux systems.
All necessary dependencies will be resolved and installed by apt.
Recommended configuration
After the installation SQL Server 2019 is not yet running on your system. Run mssql-conf setup command and follow the prompts to choose your edition and set the password of the super-administrator (sa) account.
sudo /opt/mssql/bin/mssql-conf setup accept-eula
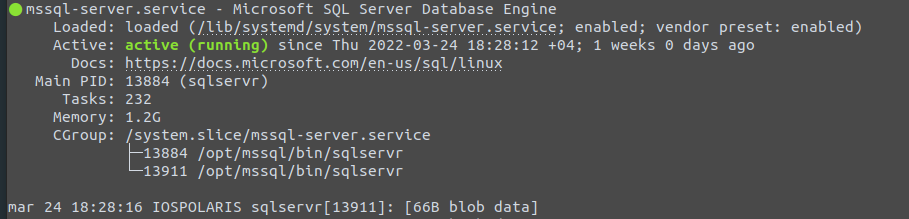
After completing the setup, verify that the service is running as expected.
systemctl status mssql-server --no-pager
Finally, add the SQL Server tools to the path by default.
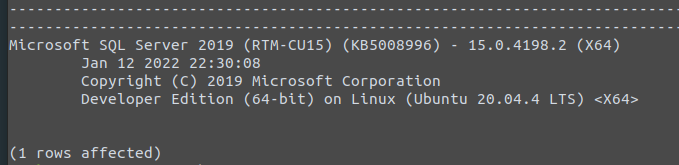
Good question. Let’s try and find out. The command-line tools of SQL Server 2019 comes with sqlcmd. The SQL Server command line tool which allows you to connect to local and remote instances of SQL Server including Azure SQL. Run the following to query the product version and edition of your installation.
sqlcmd -S localhost -C -U SA -Q "SELECT @@VERSION"
You will be prompted to enter the password of SA. If you are not familiar with the various command line switches, run sqlcmd -? to get a quick overview.
The resulting output should look similar to this.
Congratulations!
All those steps could be merged into one script to simplify and eventually automate the installation of SQL Server 2019 and its command-line tools. Interestingly the Microsoft documentation has an article on that matter.
However the presented bash script needs some serious TLC and updates. I suggest that you have look and take it as a starting point only, if needed.
Missing SQL Server Management Studio?
While working with SQL Server on a Windows system the common choice would be SQL Server Management Studio (SSMS) in order to connect to the database server / instance and the database itself. Unfortunately, SQL Server Management Studio is not available on Linux. And probably won’t be in the near (and far) future.
There are at least two possibilities to replace SQL Server Management Studio which offer sufficient and similar comfort on Linux.
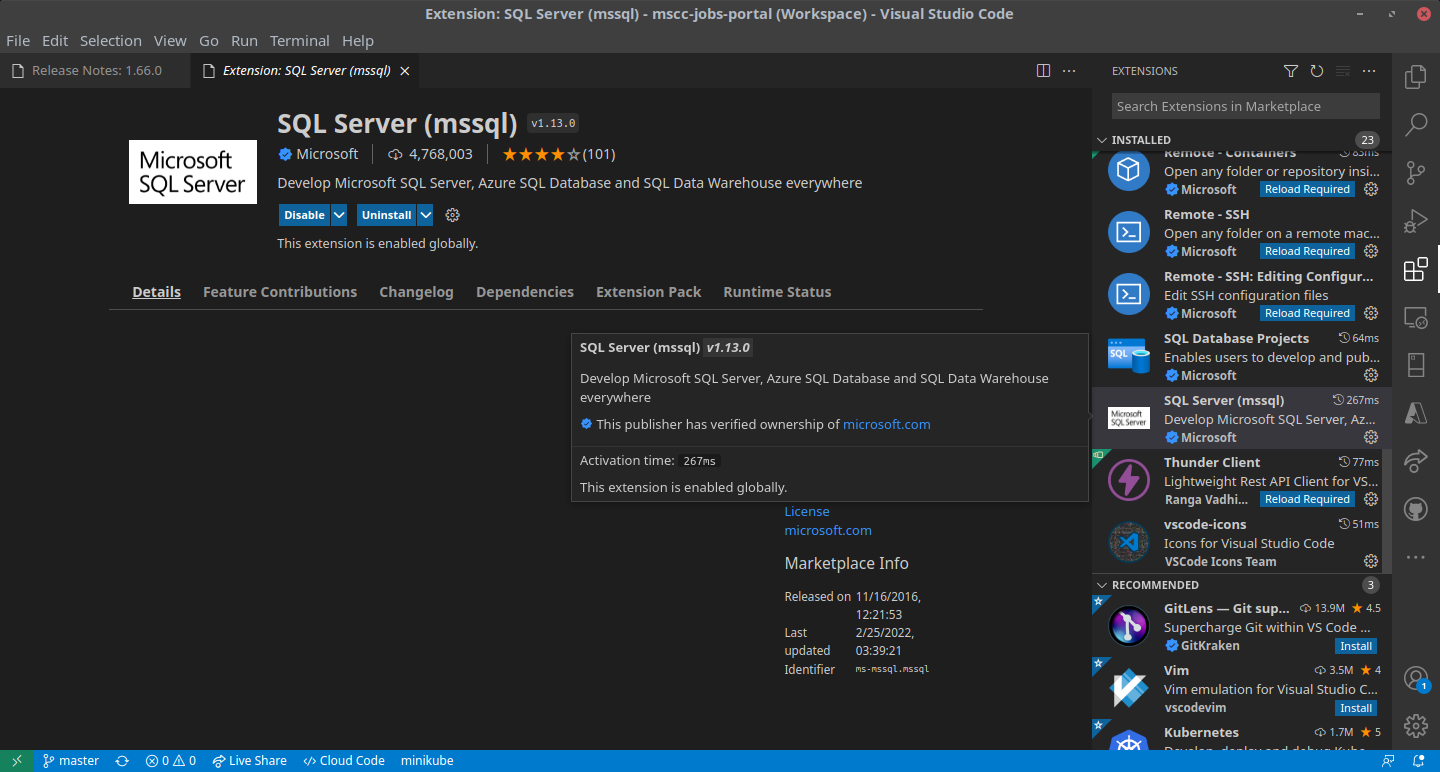
Visual Studio Code with SQL Server (mssql) extension
Azure Data Studio
Azure Data Studio and Visual Studio Code shown in the application menu
Both applications have their pros and cons. If you are already developing and writing code in Visual Studio Code you might probably prefer to use the extension and to stay within the same window. In case that you are more into SQL Server handling and Azure you might opt-in for Data Studio.
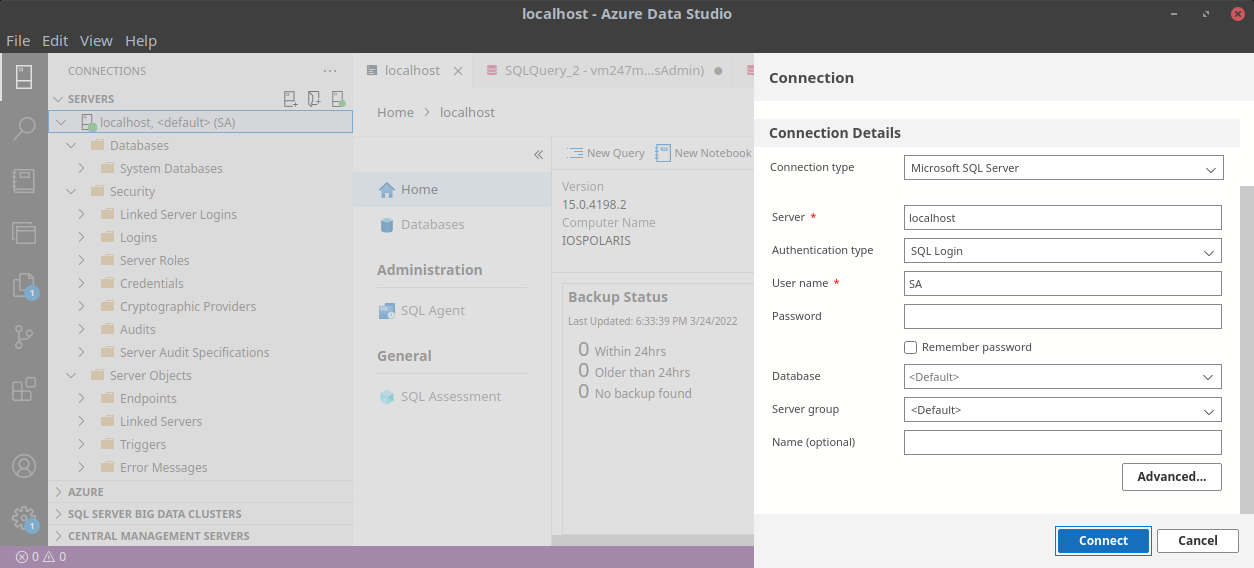
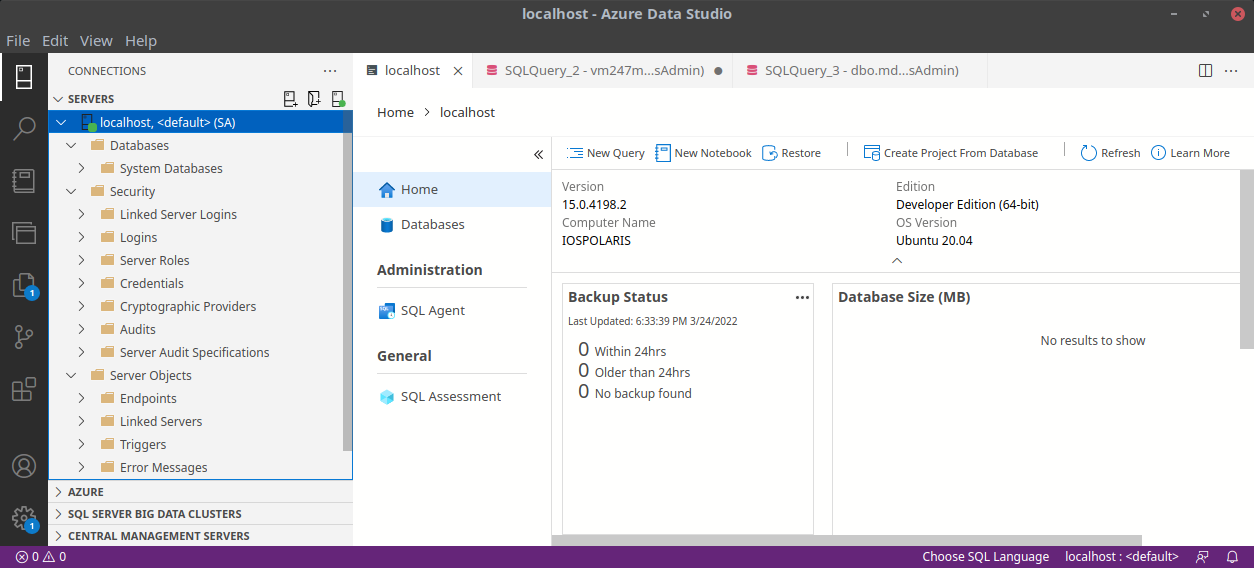
Download and install Azure Data Studio following this article.
I tested the Leap 15.4 Beta GNOME Desktop today on a Lenovo ThinkPad X250. The installation went through without any hiccup and I documented every step of the installation in a Twitter thread.
Lenovo ThinkPad X250 and a bootable USB drive w/ openSUSE Leap 15.4 Beta
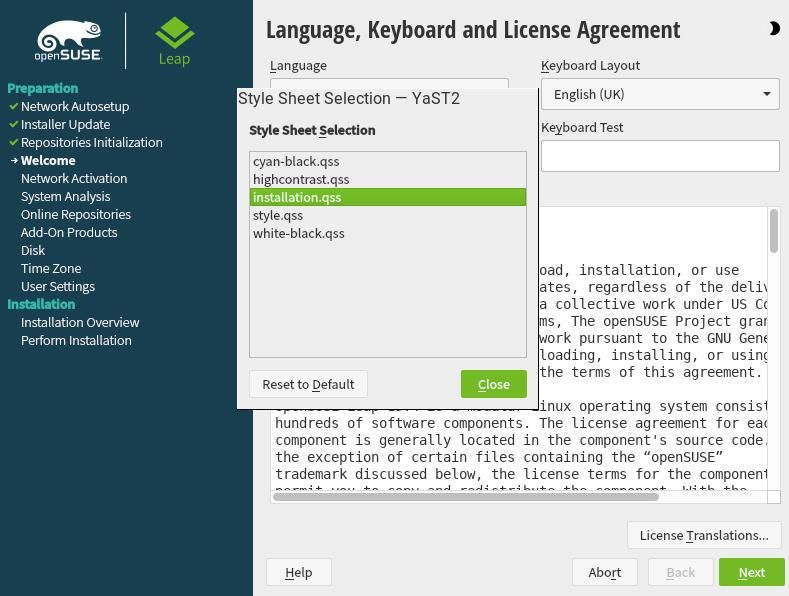
One thing that I noticed was new in the installer is the icon to change the color theme during installation. This was not present when I tested the Leap 15.4 Alpha distribution.
On the top-right corner of the installer there is a moon icon which can be clicked to select a different theme for the installer. Five themes are available which contain three dark and two light variants.
The default theme is set to the installation.qss style sheet.
The cyan-black , highcontrast and white-black are dark themes while installation and style are light themes.
highcontrast.qsswhite-black.qss
I took the above screenshots using the Leap 15.4 Beta image on VirtualBox to get clear images. In the Twitter thread I took pictures of the installation process and the theme selection on a laptop.
We had a meetup in the conference room of Flying Dodo, Bagatelle, on Saturday 22 Junuary 2022. Luboš Kocman, the Release Manager for openSUSE, who came to Mauritius on vacation was kind enough to spare a few hours and meet us.
Nirvan Pagooah, the Secretary of the Linux User Group of Mauritius, made the announcement of the meetup on the LUGM discussion list. Due to sanitary restrictions imposed by the government we could not make the meetup public. We had to keep it a private event with a limited number of attendees.
Grateful to everyone who made it despite the short notice
Luboš told us about some new things that will be coming to Leap in the future. He explained his role as a Release Manager for openSUSE and how the community as a whole is regarded as a SUSE partner. He explained the relationship between SUSE and the openSUSE community. He also talked about SUSE Liberty Linux, a new offering by SUSE which offers support for mixed Linux environment, like RHEL, CentOS and SLES.
Luboš showed us code.opensuse.org/leap/features/issues where community members can request the features they want most in openSUSE Leap. Hence, contributing to making openSUSE distributions better.
I asked whether the feature requests for Leap won't make it such that Leap and Tumbleweed will have different features. Luboš opened opensource.suse.com/legal/policy and explained that the contributions land in Factory first. He talked about the binary compatibility between Leap & SLES and users can test on Leap then migrate to SLES at total ease.
We talked about contributing to open source. Luboš mentioned non-code contributions and how easy it is to contribute to openSUSE. Ajay Ramjatan, one of the founders and the current President of LUGM, mentioned that years ago this is what he's been telling Linux & FOSS enthusiasts, that contributions can be in any form, like designs, translations, etc.
On that note Avinash Meetoo added that the Mauritian Creole (kreol morisien) can be an interesting FOSS project if we would consider adding Kreol support to openSUSE. He mentioned that there are people who are well versed on the topic but might not be techie, that is where we can work together and make this happen.
Renghen Pajanilingum shot a few tech questions, from containers to programming languages & having to compile software using different versions of packages. I know Renghen does not like to spend time fixing the distro problems because he'd rather spend that on actual work. However, he is one of the several Linux people that I have tried to lure to the green side. 😁 Not there yet but I am hopeful that we'll paint his laptop green one day.
I cannot end this blog without thanking Joffrey Michaïe for sponsoring a round of beer (and other drinks) for everyone.
At around 5 p.m the meetup ended.
Some of us stayed at Flying Dodo for more beer and to have dinner. Finally, we went to Mugg & Bean for a coffee and continued chatting about work, life and the balance. At 8:30 p.m, the hotel's taxi came for Luboš.
Yesterday, in a post, the Linux Mint project leader, Clément Lefebvre (Clem), announced a partnership with Mozilla. In a small set of FAQs, Clem tried to address most of the immediately raising questions. He even answered questions in the comments section to make things as clear as possible.
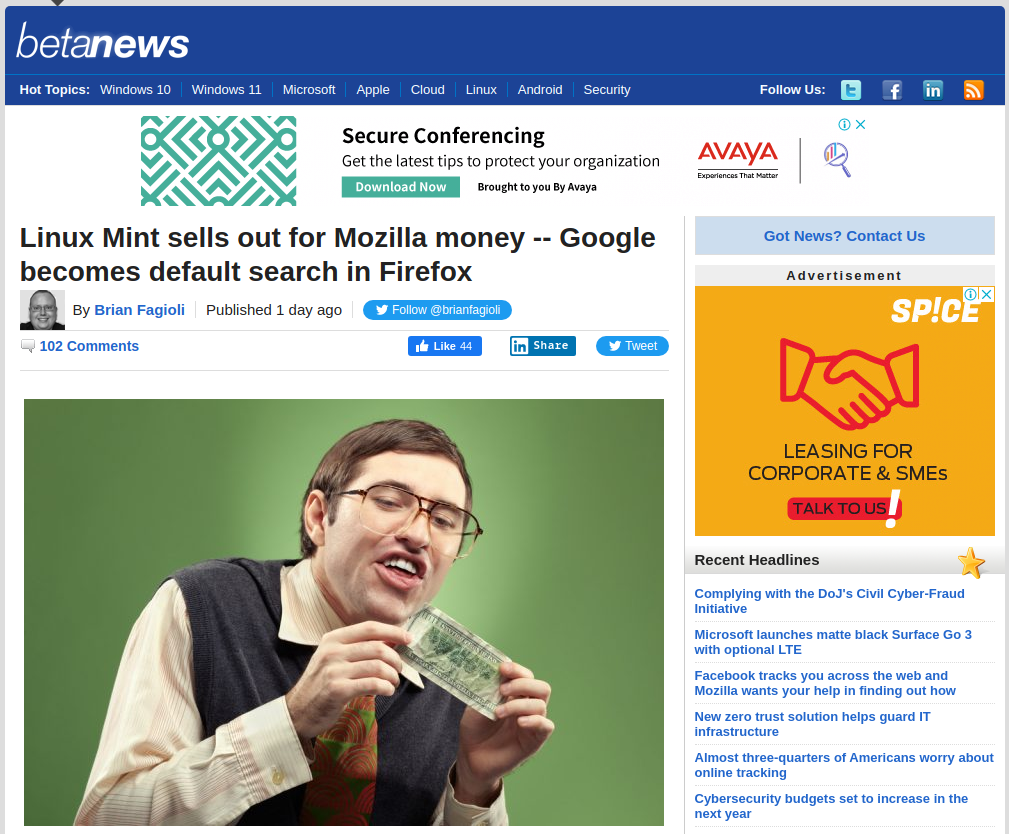
However, I saw two articles that I would say have misleading titles. One of from betanews.com and the other published by omgubuntu.co.uk. I'm not judging the article authors but I believe the titles should have portrayed the actual Linux Mint announcement.
betanews.com screenshot taken on 12 Jan 2022OMG! Ubuntu! post on Facebook
OMG! Ubuntu! says big changes coming to Firefox on Linux Mint, while the actual changes mean:
The default start page no longer points to https://www.linuxmint.com/start/
The default search engines no longer include Linux Mint search partners (Yahoo, DuckDuckGo…) but Mozilla search partners (Google, Amazon, Bing, DuckDuckGo, Ebay…)
The default configuration switches from Mint defaults to Mozilla defaults.
Firefox no longer includes code changes or patches from Linux Mint, Debian or Ubuntu.
The above list of changes are the exact ones posted by Clément Lefebvre and let's be honest these do not look like big changes. Anyone not liking the Firefox defaults can still change them to what they prefer and those who had made changes to the Firefox config previously, their preferences will be preserved and not overwritten.
Firefox 96.0 released
Yesterday, Firefox 96.0 was released and in an article, Phoronix talks about the browser's performance. In the same article, the author, Michael Larabel mentioned the Linux Mint/Mozilla partnership announcement without any ambiguity. I quote:
[…] Linux Mint announced on Monday they signed a partnership with Mozilla. Financial details were not disclosed but Linux Mint's Firefox build will be changing its default start page, the default search engines will change to Mozilla search partners, and other modifications for Mozilla.
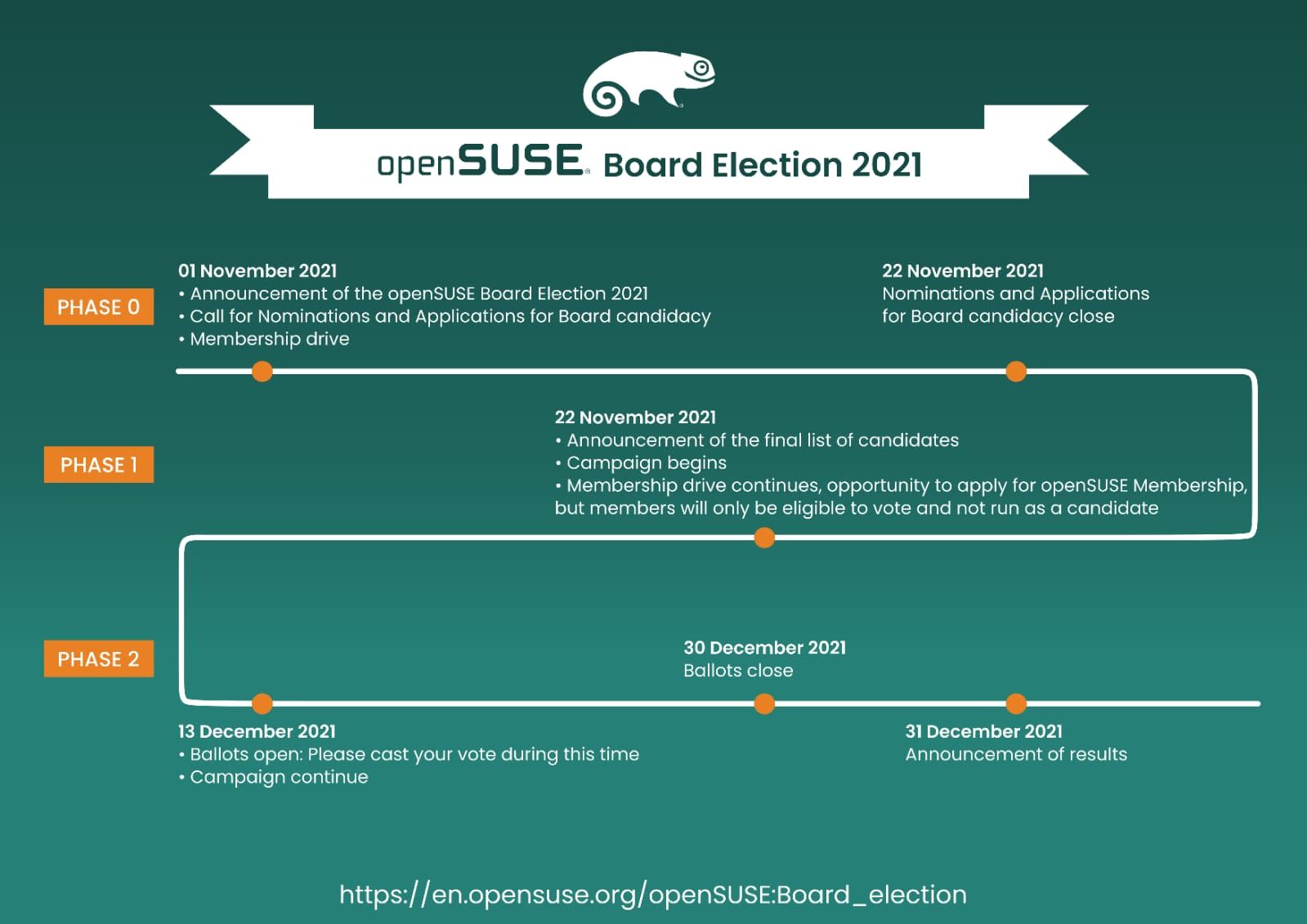
The election was announced on the project mailing list on the 1st of November 2021. The current Election Committee is composed of Ariez Vachha, Mohammad Edwin Zakaria and myself.
This election is required to fill two seats on the openSUSE Board, as the term for Simon Lees and Vinzenz Vietzke are coming to an end.
To learn more about openSUSE membership, check out this wiki.
Election poster by Kukuh Syafaat / openSUSE Indonesia
As the initial nominations/applications phase ended, we had only two members who expressed to run for this election. They are:
• Attila Pinter • Maurizio Galli
Since, we had only two candidates for two available seats, we extended the nominations/applications phase for another two weeks, giving other members the chance to toss the names of people who'd they wish to nominate. However, even after the two weeks, we were still left with only two candidates and therefore, as per the election rule about insufficient nominations, we started the election and each candidate is required to obtain 50% of votes to be considered a winner.
The ballots were opened on the 13th of December and openSUSE members received their voting URL/credentials by email. They can vote until the 30th of December at 23h59 UTC. Ballots will close on 31st December at midnight and a few hours later the result will be announced.
ubuCon Asia is a community event organised by the Ubuntu LoCo teams of the Asian region. It is a virtual conference that started today, 25 September 2021 and will last till tomorrow.
Attendees need to register on eventyay.com and get a conference ticket for free before they can access the meeting rooms. There are two meeting rooms with presentations happening simultaneously like the usual conferences.
I attended this morning's keynote which was delivered by Ken VanDine, Engineering Manager at Canonical. Ken gave a brief about what's happening with the Ubuntu community. He highlighted the features of the upcoming release of Ubuntu 21.10 Impish Indri scheduled for 14 October, less than a month away.
Ken VanDine delivering the ubuCon Asia 2021 Keynote
He mentioned that in the recent Beta release of Impish Indri users will notice that the Firefox browser is a snap package rather than the usual deb packaged. He explained the choice as being a collaboration between Mozilla and Canonical developers.
He talked about Ubuntu's choice of Flutter to develop native apps. The current Ubuntu installer is a Flutter application. He showed a demo of how to install the Flutter SDK and Visual Studio Code on Ubuntu using the Software Center. He then installed the Flutter extension and brought up a quick demo app on Flutter.
It is good to note that there is a yaru-flutterpackage that provides the look & feel of the Ubuntu system theme to Flutter apps.
Canonical has been pushing Flutter as the choice of native app development on Ubuntu since quite some time now and with the demo by Ken VanDine it becomes apparent how effortless Flutter development is on the Ubuntu desktop.
Some nice sessions are planned today and tomorrow, giving Linux users tips and tricks that they can use daily. Many of the sessions are done in native languages like Bahasa Indonesia or Japanese with English transliteration.
Tomorrow at 08h45 MUT, Kukuh Syafaat, a friend from the openSUSE Indonesia community will present Snap in MicroOS.
Snap is a package manager for containerised software packages. It is used mainly by Ubuntu derivatives. Kukuh Syafaat will explain how to use Snap in openSUSE MicroOS, a Linux distribution designed mainly for container hosting. However, there has been efforts into having a MicroOS Desktop with an immutable OS concept. MicroOS Desktop comes with Flatpak pre-installed. It'll be nice to see support for Snap as well.
GNOME 41 was released on 22 September 2021, i.e yesterday. A few major tech blogs spoke about it, some of them lengthily, testing and describing the new features.
I know for sure that GNOME 41 will be available to openSUSE Tumbleweed users in the next few days. However, I wanted to give it a spin ahead of its availability in the Tumbleweed repos. GNOME provides an ISO that bundles its latest version. It's called GNOME OS and it is available at os.gnome.org. The site provides a disclaimer that this is a pre-release software intended for testing and development. It should not be used for production.
Bear in mind that GNOME OS is not a live distribution but an installer. Therefore, if you're just trying out things then you should install it in a virtual machine.
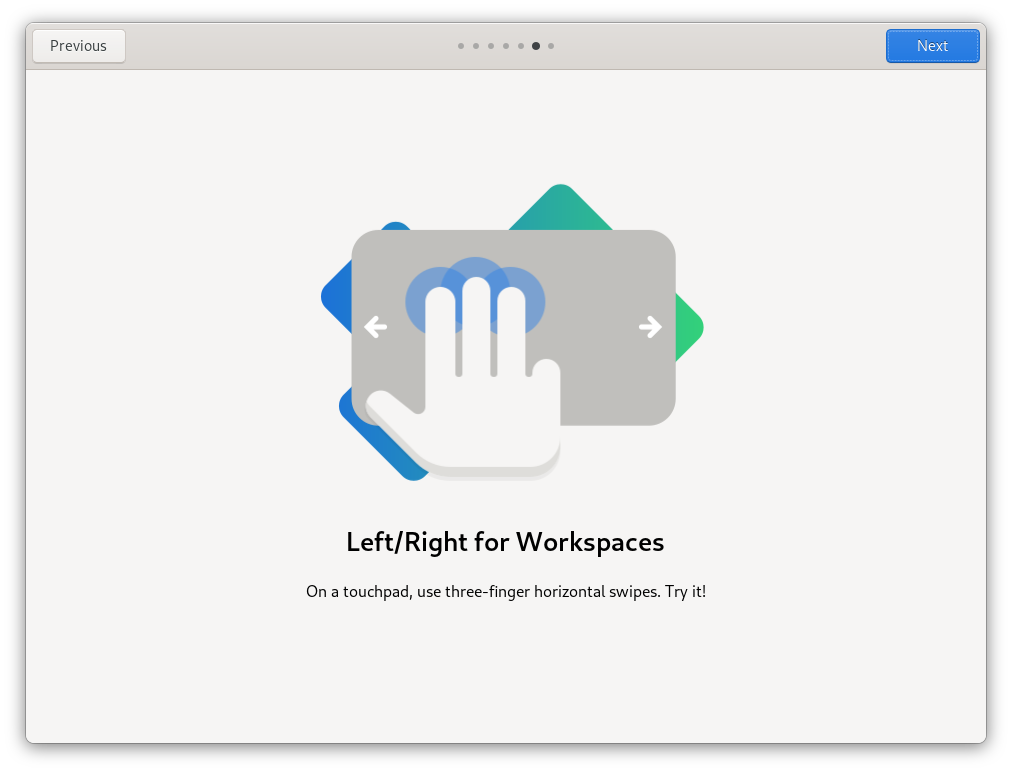
GNOME 41 proposes a quick tour upon the first log in. It's just a couple of image slides that mention some of the new features. One of the hot takes in this version is the three-finger gestures for swiping workspaces.
GNOME 41 tour on GNOME OS
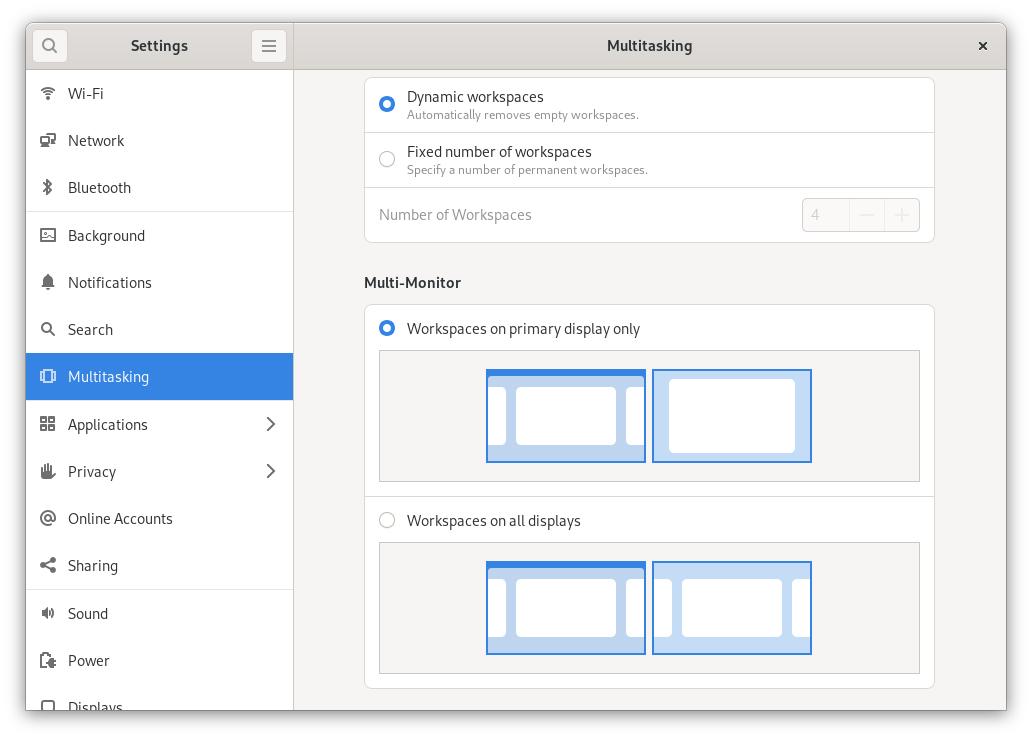
The GNOME Control Centre, commonly known as simply Settings in most Linux distributions, received updates too. It has a new panel called Multitasking which allows the user to configure the behaviour of the screen corner & edges, e.g disabling the Hot Corner.
Multitasking panel in the GNOME Control Centre
The Multitasking panel also allows the user to set the workspace as dynamic or set it to a fixed number.
I like these new features and I am certainly eager to see GNOME 41 land in Tumbleweed. 😊